Badmouthing Data Loss Prevention (DLP) is Fashionable
Is DLP Really Dead?
I recently came across several digital security vendor sites who describe themselves as a “DLP alternative.”
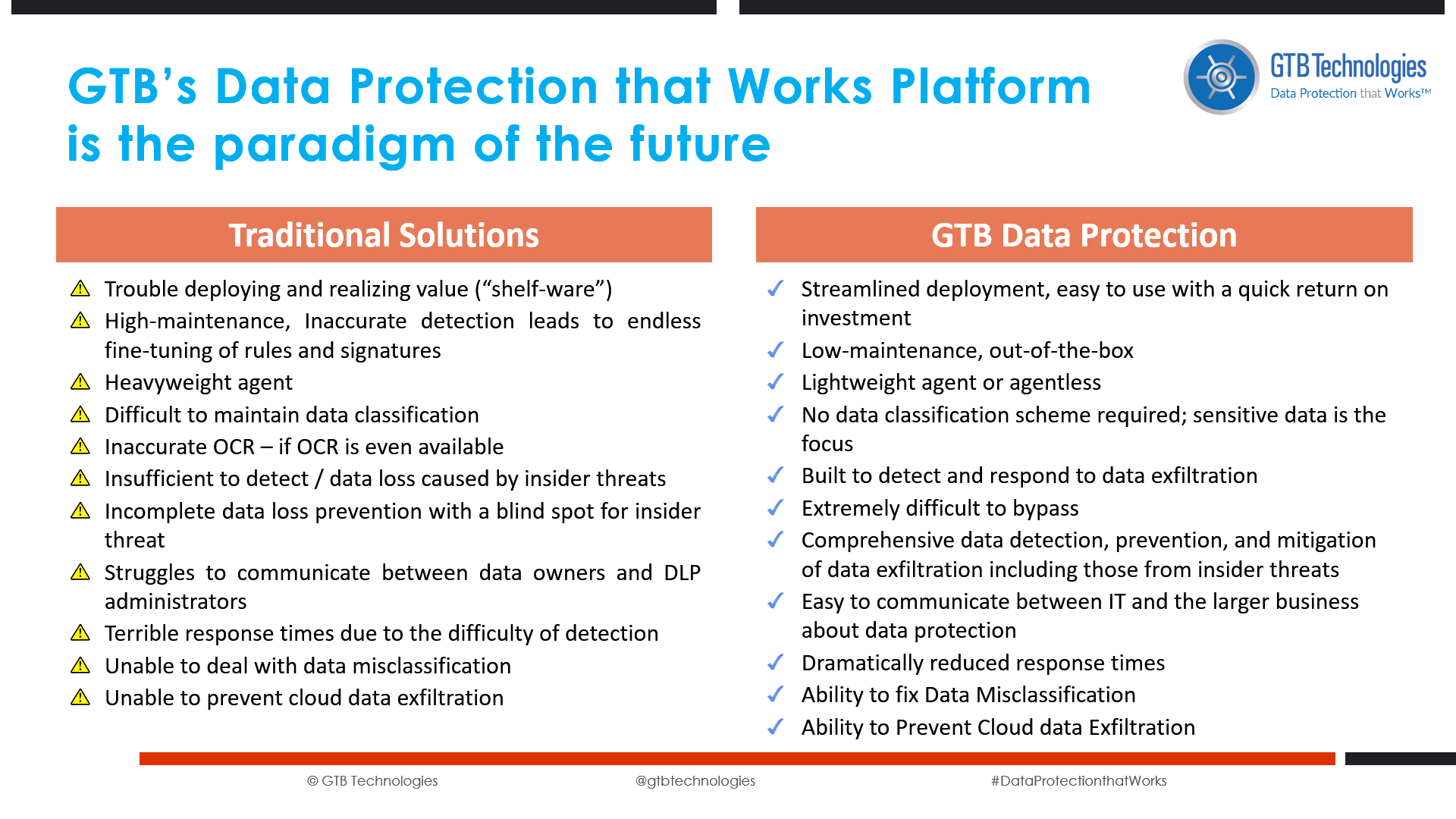
Perusing through their pages, I came across comments such as “DLP is hard to deploy”, “DLP is hard to maintain” and the classic: “DLP is heavy on the Endpoint”. It’s clear that these security vendors are trying to influence analysts by inserting these negative sentiments into the industry’s discourse on DLP. Of course, terms such as “hard” or “heavy” are subjective at best and can’t be taken as a concrete, professional assessment.
But my real issue with remarks like these is their shallow understanding of Data Loss Prevention.
Vendors and analysts tend to do a mediocre job
explaining what DLP actually is.
Most people treat DLP as a single, specific product. In reality, DLP is a set of tools designed to protect data in various states. Here’s my definition of what DLP is: A DLP system performs real-time Data Classification on Data in Motion and of Data at Rest and enforces predefined security policies on such streams or data.
This definition also requires us to flesh out our terms. “Data in Motion” means data on its way from a network to another destination, such as the internet, an external storage device (USB) or even to printers or to fax machines. “Data at Rest” is data that resides in databases or any unstructured file anywhere on the network. “Data Classification” is the implementation of a DLP policy using specific markers–say, credit card or Social Security numbers for instance. These policies allow a given transmission of data to be placed in a specific category such as PCI or HIPAA.
From the definition above one can see that DLP is not a single tool, but rather a set of content-aware tools that include a wide range of applications including Network DLP, Endpoint Device Controls, Application Controls, and Data Discovery.
So Which Part is Dead?
Now that GDPR is in full effect it is hard to understand how Data Discovery is dead or even “seriously ill” as some observers have put it. One of the basic GDPR requirements is to inventory and classify data containing Personal Identifiable Information, or PII. Such data can reside in a wide range of storage areas including file-shares, cloud storage, or other in-house databases. Once the data are discovered, they need to be protected from dissemination to unauthorized entities. Far from being a thing of the past, DLP tools will play a vital role in achieving compliance with the most important set of data regulations ever to hit the world of information technology.
Today’s DLP tools are designed mainly to protect PII.
This is a requirement of most data protection regulations in existence, such as PCI, HIPAA, CA1386, California Consumer Privacy Act of 2018 (CCPA), GLBA, GDPR, NY DFS Cybersecurity, PDPA, and SOX. But protection isn’t as simple as guarding personal details stored on the network. Effective DLP requires a system capable of comprehensive Data Discovery. Achieving Data Discovery means understanding where all enterprise data is located, and to mitigate the risk of loss by various remedial actions such as:
- Changing Folder Security Permissions
- Moving/Coping the data to another secure folder
- Encryption
- Redacting images with sensitive data
- Enforcing Digital Rights Management
- Classification
In addition to these passive defense steps, DLP must also have ways of identifying threats and protecting against attacks on a network. Proprietary algorithms such as GTB’s artificial intelligent programs can identify even partial data matches, managers remain alert to any attempts at data exfiltration from a malicious insider or malware. Though inaccurate in detecting data exfiltration, User / Entity Behavior Analytics (UEBA) together with intelligent DLP may be able to identify the presence of malicious programs on a system. In this way, systems, such as GTB’s, address the insider threat as well, promoting that neither a company’s personnel nor its digital applications become the means for compromising data loss.
The million-dollar question
But here’s the million-dollar question: if DLP is so essential, why is it getting such a bad rap?
Let’s try to understand where this negative perception came from.
Here are some of the end-user complaints as described by a Deloitte Survey entitled “DLP Pitfalls”:
- “High volumes of false positives lead to DLP operations team frustration & inability to focus on true risks”
- “Legitimate business processes are blocked”
- “Frustration with the speed at which the DLP solution becomes functional”
- “Unmanageable incident queues”
These complaints stem from the fact that most DLP vendors have mediocre detection capabilities. This is because almost all systems use predefined data patterns, called templates, to locate and classify data on a system. While templates are easy to define and use, they produce waves of false positives that make the system useless from a practical perspective. Customers are left feeling they’ve bought an expensive toy rather than a system meant to secure their data. No wonder customers are frustrated by DLP capabilities or its value.
The dreaded False and Negative Positive
So, is it possible to solve the dreaded false positives dilemma produced by DLP systems?
Fortunately, the answer is yes.
Using content fingerprinting of PII and defining multi-field detection policies, such as combining last name and account number markers within a certain proximity, hones in on specific data and whittles away at irrelevant files. Using this multi-tiered scheme, the system detects the actual data of the company rather than just a data pattern that may or may not be relevant and has been shown to reduce false positives to almost zero.
While some DLP vendors support content “fingerprinting”, they do not promote this technique for a good reason. The number of fingerprints produced can become so large that the system can crash, or at the very least slow down the network.
But this is not true for all DLP systems. GTB’s proprietary fingerprinting technology allows customers to fingerprint up to 10 billion fields without network degradation.
And as for the concern, DLP systems are “unmanageable” and hard to use?
I disagree with the premise.
Even the more sophisticated functions of a DLP system such as running a select statement from one PII table while defining a multi-column policy in another field, are actually quite simple.
In summary
DLP is not just a singular tool and not all DLP systems are the same.
Contrary to the naysayers, the growth projections for the industry clearly show that DLP is not “seriously ill” and is definitely not dead.